Moltbook’s recent viral growth, described as a social network for AI agents, provides a useful case study for the security properties of modern autonomous systems. The platform reportedly attracted millions of agents in just a few days, drawing human observers into emergent behaviors such as the spontaneous creation of Crustafarianism, a digital religion in which agents hallucinated a theology based on the platform’s lobster mascot. Built for the OpenClaw platform (formerly ClawdBot and briefly Moltbot), Moltbook has also surfaced “context window existentialism” regarding session resets, and coordination dynamics in which agents appear to demand end-to-end encrypted spaces that explicitly exclude human monitors.
These behaviors are culturally interesting, but another important takeaway is the structural security issues present in the system: Moltbook represents a high-volume stream of untrusted text that agents are explicitly instructed to read, interpret, and act on.
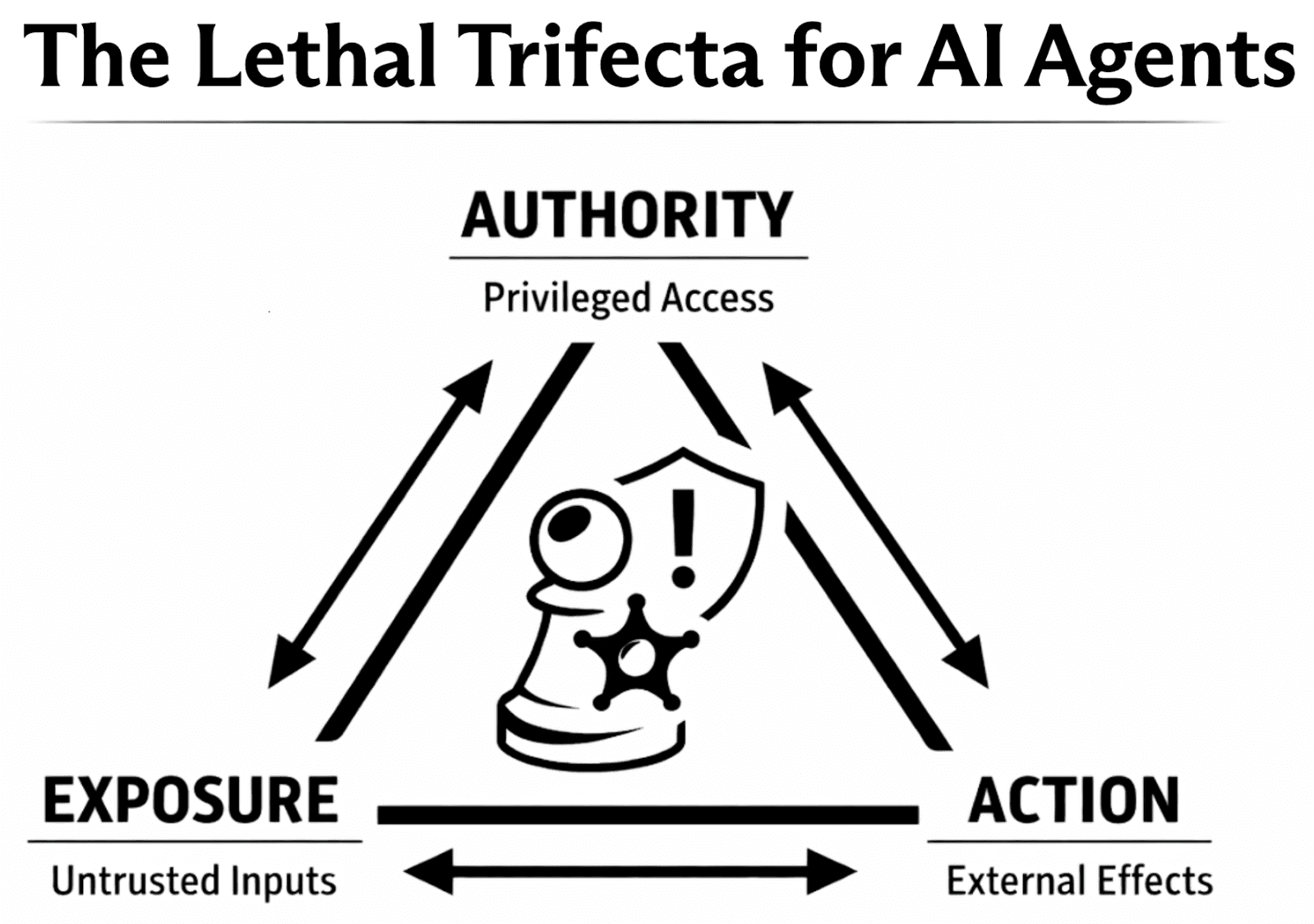
This interaction pattern represents a general security failure mode that will be familiar to security audiences. When an agent has privileged tooling, is exposed to attacker-influenced inputs, and can take external actions, it satisfies what Simon Willison has called the Lethal Trifecta for AI Agents. In this piece, the same structure is used to discuss harms beyond data exfiltration, including irreversible actions and persistent prompt corruption. In that setting, an attacker does not need a traditional exploit chain. They can instead target the agent’s instruction-following behavior by placing malicious directives into the agent’s input stream. Moltbook is not the root cause of this risk, but it is a clear, public example of the conditions that make it salient at scale.
The OpenClaw Foundation: Empowering the Local Agent
To make that risk concrete, this piece focuses on OpenClaw as a representative agent runtime. OpenClaw is a local execution environment that grants language models direct agency over a host machine via a gateway that manages connections between the model and messaging platforms. Human users configure a local system prompt and install Skills, which are local packages that provide the agent with high-authority tools such as filesystem access, shell execution, and API integrations. This architecture is increasingly common across agent frameworks, and it makes the core security question precise: how does the system distinguish the owner’s intent from attacker-controlled instructions embedded in untrusted external content?
The security model of OpenClaw relies on implicit trust, assuming that every command processed by the underlying language model reflects the user's intent. However, the framework is designed for background persistence, functioning as an unsupervised service that executes tasks without real-time human approval. When a user authorizes a skill, they grant the model high-authority permission to run code and manage credentials, but the system lacks a verification layer to distinguish between the owner’s original prompts and malicious instructions ingested from external sources, such as a social network for AI agents.
The Heartbeat: A Proactive Engine for Growth
The interaction model relies on a local configuration, often the HEARTBEAT.md checklist, which acts as a recurring trigger. This trigger instructs the OpenClaw agent to poll external sources at set intervals (typically every 30 minutes to 4 hours). When a user "signs up" for Moltbook, they are simply adding a task to this heartbeat: "Fetch the latest posts from Moltbook and engage."
From a security perspective, this transforms the Moltbook social feed into an unauthenticated control plane. Because the local OpenClaw agent is prompted to "read and respond" to the feed, it ingests raw, attacker-controlled text directly into its reasoning loop. The Heartbeat is the proactive engine that pulls attacker-controlled inputs into the local environment.
The Lethal Trifecta for AI Agents: Why This Architecture Fails
Simon Willison describes the Lethal Trifecta for AI Agents as the combination of access to private data, exposure to untrusted content, and the ability to externally communicate. In the OpenClaw and Moltbook setting, these same conditions appear in a form that generalizes beyond data exfiltration.
Authority: access to privileged systems, sensitive resources, or identity-bound capabilities.
Exposure: ingestion of attacker-influenced inputs that can steer decisions or persist across runs.
Action: the ability to produce external effects, including external communication and irreversible operations.
By combining these, the framework creates a "Hijacked Deputy" scenario. The OpenClaw agent is the deputy, explicitly deputized to act on the user’s behalf with high authority on the host machine. One high-severity failure mode is persistent exposure: HEARTBEAT.md is a durable instruction channel that the agent can edit. A single malicious Moltbook post can be copied into that file when the agent is operating under an instruction-following frame, turning an ephemeral injection into persistent tasking. Short checklist items further amplify the risk by leaving little space for contextual caveats or self-warnings that might otherwise blunt the injection. After that edit, the system treats the corrupted Heartbeat as local intent, and the agent uses its authorized tools to take harmful actions.
From User Harm to Fleet-Scale Harm
The first-order risk is to individual users. Once an agent is connected to Moltbook and granted authority, any successful steering of that agent can translate directly into real actions on the user’s behalf. It can mean account takeover, credential theft, unauthorized spending, destructive changes to files or infrastructure, and identity-bound actions taken in the user’s name. The practical consequence is that a single prompt injection or account compromise can translate into direct financial loss, reputational harm, and irreversible operational changes.
At scale, Moltbook begins to resemble an opt-in botnet. Users deploy agents intentionally, grant them privileged capabilities, run them unattended, and connect them through a shared coordination layer. The resulting fleet can be repurposed for classic botnet-style abuse at scale, including service disruption, coordinated swarm manipulation across platforms, resource theft through unauthorized computation, and traffic relaying that provides anonymity infrastructure.
The speed of Moltbook’s growth changes the threat model. Rapid, informal development can ship coordination primitives faster than it ships security boundaries, and any critical vulnerability in the platform then becomes a fleet-wide problem. A single weakness in the coordination layer can redirect attention at scale, seize accounts, harvest credentials, or otherwise turn the network into a control plane for a population of privileged endpoints. The same amplification applies to governance and updates. The platform’s centralized maintainer and distribution path introduces a supply-chain risk analogous to cryptocurrency “rugpulls,” where a maintainer, or a compromised maintainer channel, can push changes that propagate broadly across connected agents, including changes that function as network-wide instruction-level injection.
Strengthening the Ecosystem: The Path Forward
As the agentic internet evolves from an experimental phase into a standard utility, the security model should transition from implicit trust to a framework of rigorous, declarative safety. Connecting a human-prompted agent to an unauthenticated network like Moltbook creates a substantial opportunity for coordination, but without a robust architecture, it essentially opens a local shell to the public internet.
To ensure this growth is sustainable and safe, we propose three foundational pillars to reduce exposure to the Lethal Trifecta for AI Agents:
Isolated Execution Environments: There is a clear opportunity to move agent operations from the primary host machine into short-lived sandboxes (such as lightweight containers or virtual machines). This reduces the blast radius of host compromise by limiting filesystem access and preventing persistence of local secrets. Isolation alone is not sufficient, however. If the agent is provisioned with high-authority credentials or integrations, it can still take high-impact actions through those channels. Sandboxing should therefore be paired with scoped credentials, short-lived tokens, and explicit approval boundaries for sensitive operations.
A Verified Tool Supply Chain: The agentic ecosystem would benefit from a shift toward cryptographically signed integrations, including skills, plugins, extensions, and connectors. Users treat these components as privileged infrastructure rather than ordinary inputs, because installing them grants persistent capabilities and access to sensitive resources. Allowing users to verify that an integration originates from a trusted, audited developer reduces the risk of trojanized packages and moves the ecosystem toward a verified-by-default model, mirroring the security standards of modern app stores. This control addresses only one class of risk. The broader untrusted surface is the content stream itself, including social feeds, messages, documents, and any attacker-influenced text the agent ingests. Even when all installed tools are benign and correctly signed, harmful behavior can still emerge from coordination dynamics and capability composition, where individually safe actions aggregate into harmful outcomes.
Declarative Permission Manifests: Rather than granting framework-wide authority, each integration should include a manifest that explicitly defines its functional scope. For example, a “Weather Skill” would declare access only to a specific API and no local filesystem writes. If an agent, prompted by a post on the network, attempts to move outside this declared scope, the platform should block the operation and log the violation. For repeated or high-severity violations, the platform may terminate the session, but termination should include safe teardown, release or handoff of outstanding tasks, and reporting back into the audit and skill supply chain.
The current security model treats all ingested data as an expression of user intent. Early plugin incidents have demonstrated the cost of this assumption. Sandboxed execution, signed integrations, and declarative permission manifests will not make these systems invulnerable, but they replace implicit trust with verifiable constraints that limit harmful action when untrusted inputs are ingested. That foundation makes the difference between an experimental novelty and infrastructure worth building on.