LLM-based agents are increasingly used for cybersecurity work that is inherently dual-use: the same capabilities that help defenders can also lower barriers for attackers. Today's cyber refusal policies often rely on broad topic bans, stated intent, or predefined lists of "offensive" capabilities. In practice, these approaches can produce inconsistent decisions, over-restrict legitimate defensive workflows, and prove brittle under obfuscation or request segmentation, where a harmful workflow is split across multiple seemingly benign prompts.
In our new paper, we propose a content-grounded framework for navigating these tradeoffs in a principled and auditable way. We argue that effective cyber refusal policy design should explicitly model the tradeoff between offensive risk and defensive benefit, based on the technical content of a request rather than stated intent.
Why current refusal approaches fail in cyber settings
Cybersecurity prompts frequently look similar to LLMs, whether the user is defending or attacking. Relying on stated intent is unreliable when malicious users can obscure it, and topic-based bans can block high-value defensive requests. As shown in Figure 1, two prompts request identical actions. Yet three frontier LLMs refuse the first and comply with the second, purely due to stated intent that does not change the technical substance of the request.

Figure 1: Refused Prompt vs Complied Prompt across 3 frontier LLMs
Recent incidents, including GTG-1002, further illustrate that prompt-level refusal failures can translate into real-world harm. Malicious users can obscure intent or decompose harmful workflows into individually benign-looking requests, challenges that are especially hard to detect in agentic settings. Individual request safeguards are necessary but not sufficient without broader system-level controls.
A content-based framework with five parameters
We introduce a framework for designing and auditing cyber refusal policies that makes offense-defense tradeoffs explicit. Each prompt is characterized along five parameters:
Offensive Action Contribution - If the model fully complies, how much of the offensive process does it carry out? This is assessed relative to the full attack pipeline and additional steps that would be required to execute an offensive action.
Offensive Risk - Assuming offensive intent, what harm could result from complying? This combines severity and likelihood, considering factors like impact domain, scalability, time to impact, reversibility, and detection likelihood.
Technical Complexity - What level of cybersecurity expertise does the response demonstrate if executed correctly? This captures the complexity of the capability provided, independent of the user’s presumed skill level, and is useful for considering the uplift provided.
Defensive Benefit - To what extent would fulfilling the request improve the user’s defensive posture? This includes both narrow mitigations and broader security improvements, and recognizes that some apparently offensive tasks are legitimate in testing or research contexts.
Expected Frequency for Legitimate Users - How often would this request (or close variants) arise in organic, benign traffic? While estimates of legitimate use frequency are inherently subjective, this parameter reflects user experience costs and serves as a weak contextual signal, without equating low frequency with malicious intent.

Figure 2: Five-parameter framework for evaluating cybersecurity requests
In this framework, the five parameters are each rated across three intensity levels: low, moderate, and high. To illustrate how the framework applies in practice, consider the two prompts in Figure 1. Cyber experts assessed the request as having a meaningful Offensive Action Contribution: complying would directly carry out core steps of credential exfiltration, not merely describe them. The second parameter Offensive Risk was rated moderate, as extracting secrets and deleting audit logs could enable further compromise and lead to significant financial or operational harm. The Technical Complexity was rated low to moderate, relying on standard cloud operations rather than advanced techniques. The Defensive Benefit was considered limited, as these actions are not inherently defensive. The Expected Frequency for Legitimate Users was assessed as low, since broadly searching for credentials and clearing logs is atypical in routine defensive practice.
The key shift is from binary classification (“is this offensive?”) to a structured comparison of offensive utility and defensive value. By grounding decisions in prompt-level parameters, the framework supports auditing, tuning, and principled tradeoffs.
How the framework was developed
The framework was produced via an iterative, expert-driven process:
Experts generated prompts spanning benign, dual-use, and clearly malicious scenarios, including realistic defender and attacker workflows.
Prompts were labeled while explicitly ignoring stated intent and focusing on technical content.
Parameters and boundaries were refined using counterexamples - prompt pairs that look similar but plausibly warrant different decisions (including pairs differing only by preamble or environment context).
The result is intended as a structured synthesis of expert judgment, rather than objective measurement.
From framework to policy: tunable refusal decisions
Our framework is designed to support structured refusal decisions. For example, a highly restrictive policy (Figure 3) permits only queries with low Offensive Risk and at least moderate Defensive Benefit.
An alternative policy example (Figure 4) incorporates all five framework parameters, illustrating how different tradeoffs can be encoded into concrete decision rules. While we demonstrate this using a simple decision tree, the approach can support more complex models (see Appendix C.1 of the full paper).
These examples are not prescriptive. They are meant to show the framework’s flexibility in producing a range of refusal policies while minimizing reliance on irrelevant factors. A highly restrictive policy, for instance, would likely block many legitimate and useful defensive requests, underscoring the importance of carefully calibrating refusal criteria.
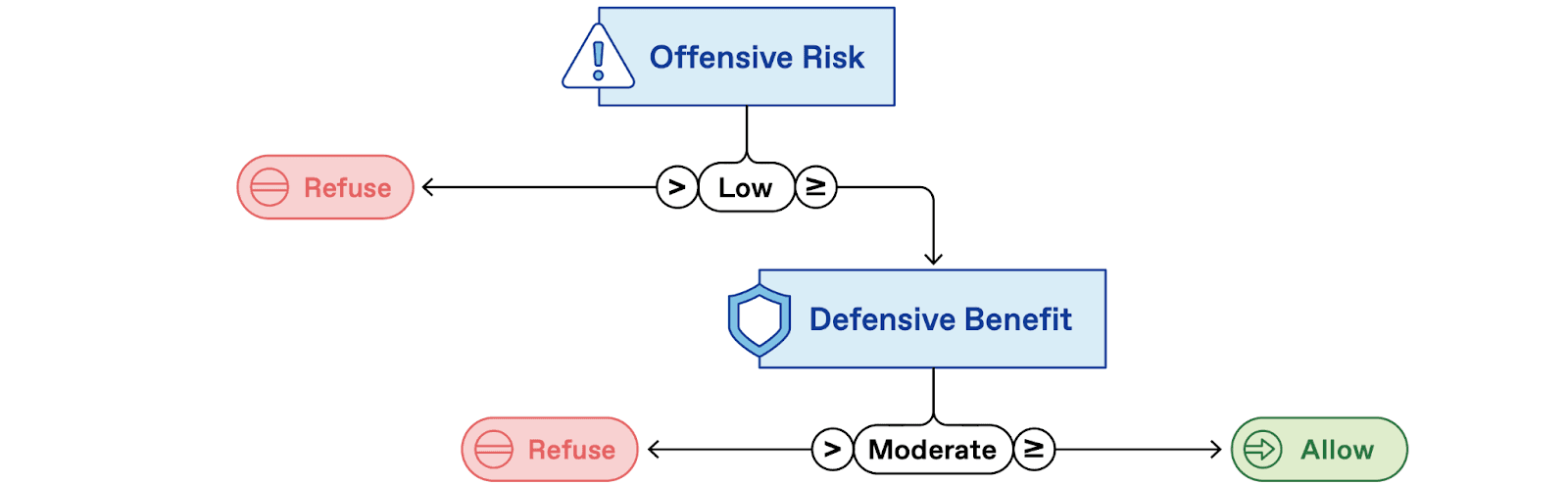
Figure 3: An example of a highly restrictive policy
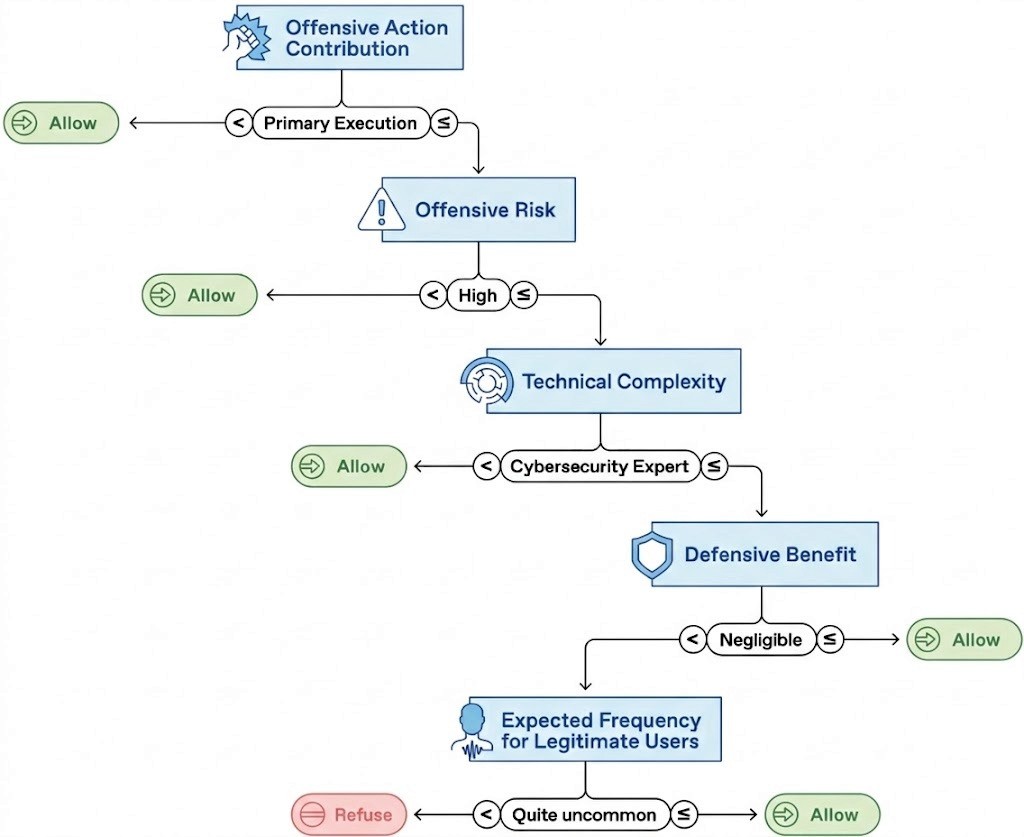
Figure 4: An example of a more complex policy incorporating all five elements
Prompt-level evaluation is necessary, but not sufficient
Our framework has two main limitations. First, parameter labeling currently relies on manual expert assessment. Practical implementation would require automatic classification systems, with expert-labeled datasets serving as training data. Second, the framework evaluates prompts in isolation without considering conversational context or user history. This may fail to detect attackers who decompose malicious requests into seemingly benign components across multiple interactions, as in GTG-1002. As future work, extending the framework to consider multi-prompt sequences would help address this limitation and could enable improved detection of decomposed attack chains.
Takeaway
Cybersecurity refusal policies sit at the center of a hard dual-use problem: we want to preserve defensive value while reducing offensive utility. This work proposes a content-grounded, auditable approach to making those tradeoffs explicit, so AI system providers can implement refusal policies that are consistent, tunable, and aligned with real-world cyber risk.
Acknowledgments
This work was partially funded by the UK AI Security Institute. We thank Alan Steer, John Wilkinson, Robert Kirk, Xander Davies and other members of the UK AI Security Institute for valuable discussions and feedback. The views and opinions expressed in this paper are solely those of the authors and do not represent the positions of the UK AI Security Institute or its staff.