We are happy to share that Irregular's CEO Dan Lahav is among the co-authors of the new Science Policy Forum paper, "The science and practice of proportionality in AI risk evaluations".
The paper advances a rigorous framework for calibrating the burden of AI model evaluations to the risk they assess. This is a three-step framework for determining whether requiring a specific evaluation is proportionate to the burden it imposes on model providers, including costs such as compute, development effort, and disruption to infrastructure or deployment.
As outlined in the paper, to be proportional, an evaluation must be: suitable, meaning it provides meaningful information about the assessed risk, necessary, meaning no less burdensome evaluation would be equally effective, and balanced, meaning its informational value justifies the cost it imposes.
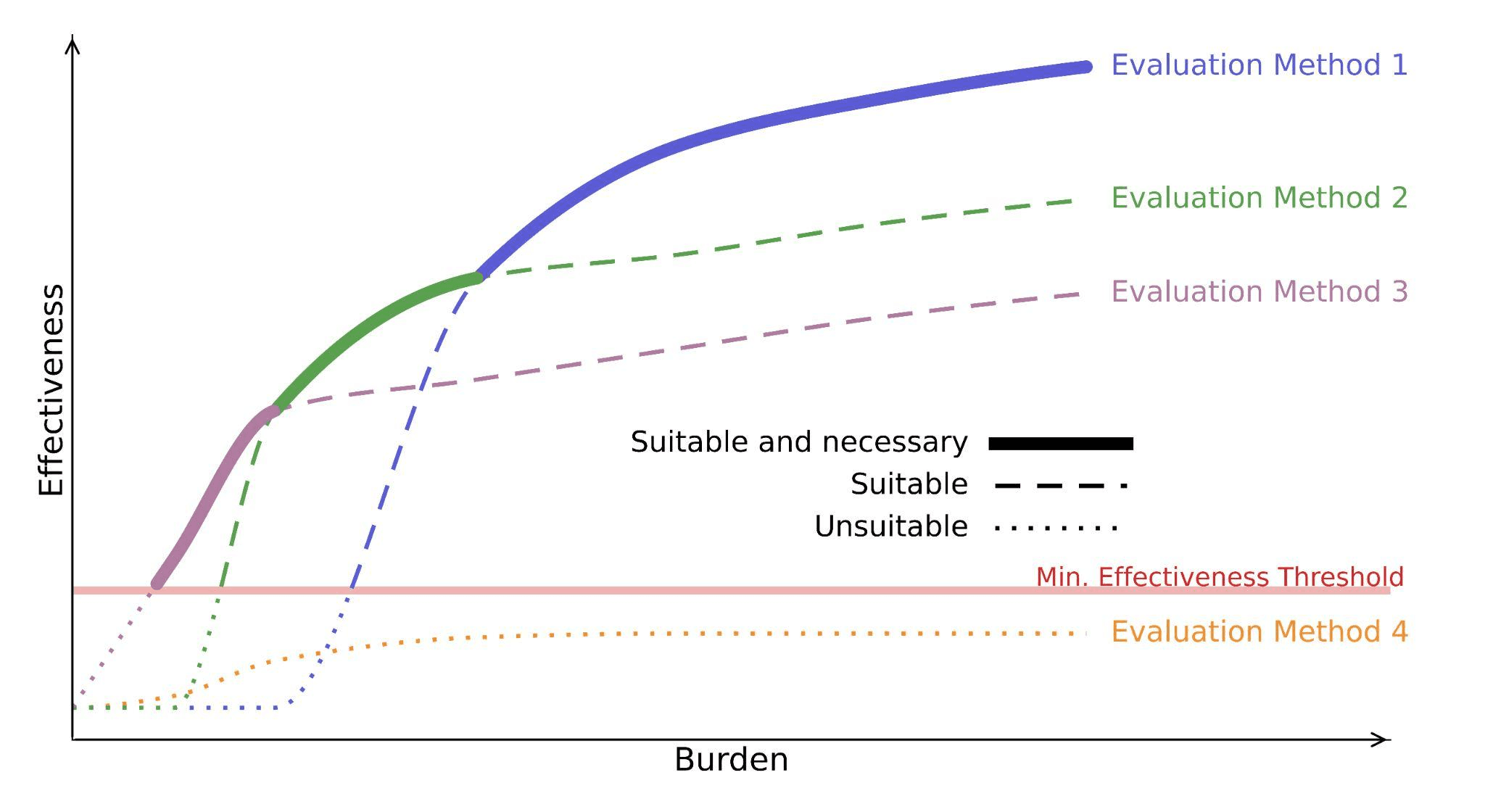
The figure above illustrates how different evaluation methods reach different levels of effectiveness at different burdens, and that not all of them are worth requiring. The Pareto frontier identifies which evaluations are necessary for a given level of effectiveness.
The paper uses AI-enabled cyber vulnerability discovery evaluation benchmarks as its working example, grounding cybersecurity as a domain at the frontier of AI risk assessment where this kind of principled calibration is essential. Irregular is glad to contribute our AI security expertise to this important conversation on evaluation standards.