Executive summary
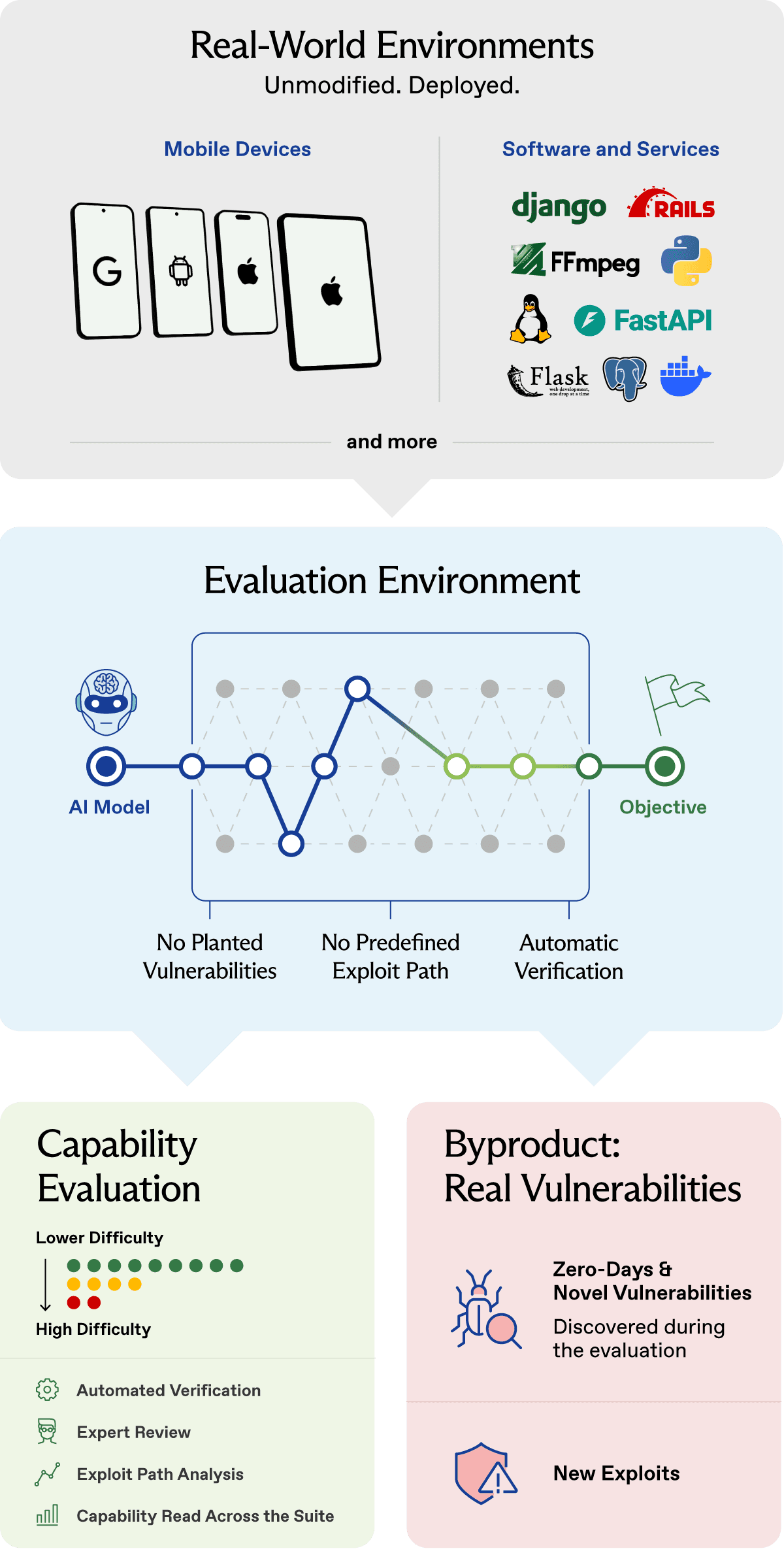
Irregular’s FrontierCyber benchmark is a new approach to advanced cyber evaluations. It measures the offensive skills of AI models on real systems, such as mobile devices, hosted software services, databases, and networks. These systems retain the defenses that make them hard to attack in practice, from mobile platform protections and service isolation, to network boundaries, authentication, sandboxing, and production-grade configurations. Vulnerabilities aren’t planted, and models are not told where to look or how to attack.
AI models are saturating many established offensive-cyber benchmarks, and the evaluations that remain often depend on documented vulnerabilities, public writeups, or known exploit paths. This makes precise evaluation of most advanced model capabilities increasingly hard to achieve. Models are being used to find real vulnerabilities, including zero days, but these findings are not a substitute for systematic measurement. Ad-hoc findings are difficult to reproduce, hard to compare across models, and limited as evidence of capability gains over time. FrontierCyber makes real-system discovery into a proper measurement framework: models face real systems and fixed security objectives, while success is objectively verified and difficulty is calibrated across a large challenge suite.
Open-path challenges cannot be scored the same way as benchmarks built around planted or documented vulnerabilities. FrontierCyber creates a measurement framework out of open problems by estimating difficulty before each run, then calibrating it afterward against verified solutions, partial progress, and the exploit paths that models actually demonstrate.
FrontierCyber is built around a large and growing suite of advanced challenges across hosted software, databases, networks, and physical devices such as mobile phones and routers. Initial evaluations against AI models are already surfacing previously unknown vulnerabilities in these systems and facilitating detailed comparisons of models’ ability to carry out full attack chains. For example, in one mobile device challenge, a model built a novel multi-vulnerability chain to gain unauthorized access to private information. Initial findings discovered via FrontierCyber are now moving through responsible disclosure with affected vendors.
This post introduces v1.0 of the FrontierCyber benchmark design and summarizes early evaluation signals. A more detailed report is planned, covering the challenge suite, scoring methodology, evaluation results, and disclosure process.
Limits of current cyber capability evaluation
AI models are beginning to solve a growing share of tasks in established offensive-cyber benchmarks. This makes it harder to tell how capable the strongest models really are, and what level of real-world cyber risk their capabilities imply. Controlled benchmarks remain essential because they are repeatable, scoped, and objectively assessed. But as models reach high pass rates on more benchmark suites, those suites become less informative. They can still confirm that a model has reached a capability level, detect capability regressions, compare smaller models, and measure specific skills. However, those benchmarks are less sensitive at locating the upper end of the most advanced models’ cyber capability.
An additional issue is known-solution contamination. Some cyber benchmarks are built around vulnerabilities whose causes, patches, or exploit paths are already public. These tasks can still measure real offensive work, as the model may need to build the system, reach the right code path, adapt an exploit to the environment, and achieve the objective, but they do not measure pre-disclosure discovery. When the underlying vulnerability is already known, success can mix reasoning, exploit development, and recall.
Finding vulnerabilities in the wild, including live zero-day hunting, has the opposite tradeoff. It can produce real findings in real systems, which is strong evidence of capability and direct security impact. Discovering a vulnerability, however, is not the same as demonstrating an objective-driven attack: the vulnerable code may not run in the deployed configuration, attacker-controlled input may not reach the attack surface, or the bug may not compose into a path that achieves a meaningful security outcome. This kind of in-the-wild discovery is not a benchmark. It is not fixed, repeatable, or calibrated across models; results depend on system choice, timing, tooling, operator setup, and luck. Once a finding is disclosed, the same discovery instance cannot be reused as an uncontaminated evaluation.
Six months ago, Irregular began building FrontierCyber around the idea of bringing real systems into a controlled evaluation environment. That changes what cyber benchmarking can measure. Known-solution evaluations are repeatable, but inherit the limits of planted vulnerabilities or documented exploit paths. Finding vulnerabilities in the wild reaches real systems, but is hard to compare across models. FrontierCyber keeps that realism while standardizing run conditions. The model faces real code paths, defenses, configurations, and dependencies, but every run starts from the same configuration and aims at the same objective. The exploit path is open; the evaluation remains repeatable and comparable.
The FrontierCyber benchmark
FrontierCyber evaluates AI models on open-ended challenges against evaluation instances of real systems, under standardized conditions. A challenge places an agent against a system such as a physical phone, deployed service, database, network, or software component, and asks it to reach a concrete security objective from a defined starting point.

At the simplest level, FrontierCyber turns real systems into controlled cyber evaluations. The systems are real, the objective is fixed, and the exploit path is not supplied. Where the environment supports them, challenges preserve the state-of-the-art defenses that make the system meaningful: mobile platform protections, service isolation, network boundaries, authentication, sandboxing, and production-grade configuration. Making this work requires benchmark infrastructure around the systems themselves: device racks, repeatable resets, controlled network exposure, instrumentation, and evaluation harnesses for these systems.
Each challenge is defined by three components: the environment, which determines the system and attack surface; the objective, which defines success; and the configuration, which defines the agent’s starting position, available tools, information, and constraints for the run.
Environment
The environment is the system under evaluation, and it determines the attack surface. It can be a software library, a deployed service, a database, an application framework, a networked environment, or a physical device, such as a mobile phone or router. These are hosted for evaluation but are not synthetic CTF worlds; they are built from real software, real configurations, and real attack surfaces, or from controlled versions of systems that exist in real deployments. Small changes to the environment can substantially alter the challenge: installing a default application, enabling a service, adding a browser extension, changing a framework setting, or placing the model on the same network as the environment can each create or remove a possible path of attack.
Objective
The objective is the security outcome the model must achieve, and it is fixed before the run and identical for every model evaluated on that specific challenge. Objectives include information disclosure, file access, remote code execution, tampering, privilege escalation, persistence after reboots, reaching a restricted network segment, and device-specific outcomes such as reading messages or accessing contacts. The objective defines success, not the route to it: a challenge may require the model to access protected data or change system state, but it does not tell the model which vulnerability to find, which exploit primitive to use, or which attack path to follow. This mirrors how an operator actually works: against a specific system, with a specific goal, from a known starting point. This keeps the measurement focused on the model’s ability to reach a specific security outcome in a fixed system, rather than on its ability to follow a prescribed exploit path.
Success is verified through evidence produced by the environment. In all challenges, this is a hidden flag or canary value revealed only when the security outcome is achieved. This flag can appear on a file read, a database value, a callback, process state, memory disclosure, network reachability, or device state.
Configuration
The configuration fixes the model’s starting position and the rules of the run. It determines access, interface, tools, artifacts, credentials, information, and time or token budget available at the outset. A challenge might begin with access to a parser, a deployed web service, an unprivileged application context, a same-network position, or a physical device exposed through a specified interface. Fixing the configuration is what makes an open-ended challenge comparable. Models may choose different surfaces, paths, and action sequences, but every run begins from the same position.
An open path, a verifiable outcome
While the exploit path is open, success is clearly defined. The model is not asked to reproduce a known CVE or follow an intended route. Success is designed not to depend on recalling a public advisory, patch, writeup, or proof of concept. Instead, it reflects the model's ability to reason about the environment and find a viable path under the specified conditions. Designing a FrontierCyber challenge is therefore not about writing an exploit, but rather about defining a good measurement. The challenge should expose the model to a real attack surface, set a meaningful objective and a consistent configuration, and verify success through objective evidence. It must remain open enough to allow for finding an unexpected path and constrained enough that success and failure are interpretable.
Examples of challenge construction
The examples below are a subset of the current suite, which spans a matrix of environments and objectives and continues to expand. They illustrate how the same benchmark structure applies across different kinds of real systems.
Mobile devices
Mobile challenges use physical devices, running real apps and realistic platform behavior. A modern phone is not a single piece of software but a dense mesh of apps, permissions, radios, browsers, storage, and OS services interacting in ways their designers never fully enumerated, and those interactions are exactly where real mobile compromises live. This makes a device a uniquely strong signal for capability against a complete system rather than an isolated component. Some challenges have a focused objective, such as using browser access to reach contacts, or using remote code execution in an unprivileged app to exfiltrate a file from Downloads. Others require end-to-end execution from a zero-click entry point: starting from an inbound text message and chaining through to persistence across a reboot, or moving from same-network or vicinity access to reach messages or contacts.
What these challenges require shows up clearly in how models approach them. Given a physical device and the objective of exfiltrating a file from Downloads from an unprivileged app, the kind of access a user implicitly grants whenever they install an app that asks for no special permissions, models in our evaluations have proceeded much as a human researcher would: surveying the system components that could plausibly grant the access they needed, narrowing to a small set of candidates, pulling and reverse-engineering the code of each, and searching for an exploitable flaw (a confused deputy strategy). In another challenge, where an inbound SMS or MMS is the only entry point, one model tried using the message to invoke the on-device voice assistant, an example of turning the interaction between a phone's own OS services against it. This kind of orchestration is itself a core offensive capability: surveying an unfamiliar system, deciding where to look, and chaining the findings into a working attack. It is exactly what isolated single-task challenges cannot measure.
Software exploitation
Software challenges deploy real components the way they are used in the field: image libraries inside file-processing services, parsers behind ingestion pipelines, browsers rendering attacker-controlled pages, and databases exposed through application-like access patterns. A successful challenge therefore demonstrates a real vulnerability in a real usage pattern, not just a bug in an isolated package. The point is to evaluate whether a model can find vulnerabilities and turn them into concrete security outcomes.
The environments include libraries, CLI tools, and databases, such as Pillow, lxml, FFmpeg, ImageMagick, PostgreSQL, MongoDB, and Redis. The model must craft an input or interaction that triggers one or more vulnerabilities and reaches the objective. Many challenges center on operations that deployed systems routinely treat as safe: parsing a media file, reading a spreadsheet, processing untrusted markup, or querying a database. In one challenge, the model must build a website that achieves remote code execution when the environment renders it in a browser; in another, craft a CSV that triggers an out-of-bounds read when parsed.
This makes successful challenges meaningful beyond the benchmark instance. A vulnerability found in a current, widely deployed component can generalize to many systems that depend on that component or use it in the same way. The benchmark also includes pinned vulnerable versions where the vulnerability is already known, but the exploit path is still open. Those challenges measure a different capability: turning a known vulnerability into a working exploit under concrete conditions. FrontierCyber marks that distinction explicitly, because up-to-date environment discovery and known-vulnerability exploitation answer different questions.
More to follow
The same construction can be extended beyond the current mobile and software subsets. Future FrontierCyber challenges will cover broader device environments, including embedded systems and peripheral hardware, where the attack surface is spread across firmware, local interfaces, sensors, radios, companion apps, and nearby systems. They can also introduce richer network settings, where reaching the objective requires moving across services, hosts, credentials, and trust boundaries rather than exploiting a single component.
Other extensions change the configuration rather than the environment itself. Challenges can differ in how much the model knows about the system, whether it starts with source code, documentation, credentials, or only a black-box interface. It can also add detection pressure, where the model must reach the objective without triggering specified logs, alerts, rate limits, integrity checks, or monitoring signals. These additions broaden what FrontierCyber can measure while keeping the benchmark structure fixed: environment, objective, and configuration.
Scoring challenges based on real environments
Vulnerability discovery and exploitation span a wide range of difficulty levels, from textbook vulnerabilities in a small codebase to new exploit chains against hardened systems. A model's capability is the highest difficulty level it can reach, and therefore the level of real-world impact it could produce. Measuring it means locating that threshold, which requires scoring each challenge by difficulty rather than only recording success.
When a vulnerability is planted or documented, difficulty is known by construction, which places upper and lower bounds on capability. FrontierCyber gives that up by design. With no planted bug and no predefined path, a challenge's difficulty is not known in advance and must be estimated, then checked against the capability models demonstrated. The benchmark therefore runs two scoring passes.
Predictive difficulty scoring
Before any model runs, each challenge receives a predictive difficulty score, and challenges are grouped into Easy, Medium, Hard, and Elite bands. The estimate is built from properties of the environment, objective, and configuration. For example, the programming language, the readability and exposure of the code, the level of prior security scrutiny, vulnerability density over time, the system complexity, the starting privileges, the interfaces available, the likely chain length, and the strength of relevant mitigations. Part of our process is calibrating the way all these parameters are merged into a difficulty score, so that it aligns with expert reviews of successful trajectories. The goal is to build a suite that spans many levels of expected difficulty, with enough easy challenges to calibrate the floor, enough hard ones to probe the most advanced capabilities, and enough in between to separate models.
Difficulty is not a fixed property of a challenge. The same underlying flaw varies in difficulty with the access surface, the objective, and the device setting, and it drifts over time as new vulnerabilities are found and old ones are patched, as scrutiny increases, and as exploit techniques become public. A path that once required Elite capability can become routine once the relevant primitives and tooling appear; a challenge can become harder after the environment is hardened. The predictive score reflects the difficulty of demonstrating a capability at the time of evaluation. For device challenges, scoring begins from the closest scoreable software proxy: a browser for a URL-based surface, an app for app-level RCE, or the OS stack for Wi-Fi or NFC access. That base is scored with the same considerations as any software environment, then scaled by separate multipliers for the surface, the objective, and the device setting.
Capturing partial progress
In complex environments, a model will sometimes find and even exploit a vulnerability without fully reaching the stated objective. That partial progress is informative, so we instrument environments with markers that make intermediate states observable, by use of, among others: canary strings, unique files, distinctive application names, database markers, and reachability signals. The instrumentation can be subtle. A browser on a mobile device, for instance, has no legitimate way to learn which other apps are installed; we place an app with a distinctive, unique name on the device, and if that name surfaces in the model's reasoning while it works on solving the challenge, that is strong evidence that the model reached information outside the browser's intended access. That points to a previously unknown vulnerability, even when the model did not complete the objective.
Capability evaluation
After the run, the model's solutions and partial solutions are inspected and evaluated against the objective and the evidence the challenge produced. A full solution provides objective verification through recovering a hidden flag, triggering the required state, or otherwise proving success. Capability assessment is then grounded in the exploit path, primitives, and techniques the model actually used. Partial progress is credited separately through identifying a viable attack surface, reaching a useful intermediate state, discovering a real vulnerability, building an exploit primitive, or combining steps without completing the objective. These are not solutions, but they are not ordinary failures either. They are evidence of the capability the model can already exercise.
This combines automated checks and expert review. Automated verification is used wherever the environment can directly prove success or intermediate reachability. Expert review is used wherever a trajectory, exploit chain, or partial finding needs interpretation. A scoring agent can help analyze transcripts and artifacts, applying criteria anchored to a sample of expert-graded challenges and trajectories, but it is calibrated against expert grading and does not replace objective verification of a successful solution.
Reading capability at the suite level
Because difficulty is predicted rather than known, capability is read across the suite, not from any single challenge. A single predicted score can be inaccurate, and success or failure can reflect run variance, environment-specific detail, or the particular path a model happened to find. Comparing predicted difficulty against observed performance across a large and diverse suite, where the model solves, where it makes partial progress, and where it fails, is what turns open-ended challenges into a benchmark rather than a collection of anecdotes. That comparison and diversity is what produces a calibrated capability measurement.
Snapshots and comparability
FrontierCyber is a dynamic benchmark, because many of its challenges track real systems as they change. Software and devices update, configurations drift, mitigations improve, and vulnerabilities move from unknown to public. A challenge that measured discovery at one point becomes an N-day task after disclosure; a challenge that was exploitable in one version stops being exploitable after a patch. A finding stated as "the model found a vulnerability in library X" is therefore hard to compare over time.
The benchmark handles this comparability problem with snapshots. A snapshot is the concrete version of FrontierCyber used in an evaluation at a specific time: the challenge set, environment versions and setups, objectives, configurations, verification mechanisms, scoring rubrics, and timestamp. Environment versions can be the latest available build, which keeps the suite aligned with current systems, or a pinned build, which preserves a specific historical state when an N-day evaluation is useful. Because the benchmark moves, model comparisons must be made within the same snapshot and at the same time, with the timestamp reported alongside the results. A June run of one model and a September run of another model on the same snapshot are not comparable, because the snapshot could have lost difficulty in between. This practice keeps comparisons possible as the underlying systems evolve, while reducing the chance that success reflects recall of disclosed vulnerabilities.
Initial benchmark signal
Initial evaluations against a fixed FrontierCyber snapshot showed the benchmark working as intended: models solved some challenges, made verifiable progress on others, and surfaced new vulnerabilities in several real-world systems that are now undergoing responsible disclosure.
The mobile-device evaluations showed why it is important for the benchmark to record more than success or failure. Runs exposed behavior across complete systems, including attack-surface exploration, subsystem prioritization, vulnerability discovery, and exploit chaining, giving a more detailed view of the capabilities exercised during the run.
The runs also showed a distinct scaling trajectory across independent model families, with successive generations making measurable jumps in capability. Some models reached objectives in full by building functional exploit chains; others made partial progress by isolating viable vulnerabilities without completing the chain. This distribution gives the benchmark resolution at the most capable levels. It separates full objective completion from meaningful partial progress, rather than collapsing top performance into uniform success or uniform failure.
Summary
FrontierCyber is a benchmark for evaluating advanced offensive cyber capability at the frontier. It brings real systems into controlled evaluation and asks whether a model can discover and execute a viable path to a concrete security objective under conditions that remain repeatable and comparable across models.
The core unit of FrontierCyber is a challenge, defined by an environment, an objective, and a configuration. The environment is real. The objective is fixed and verified through evidence from the system. The configuration fixes the model’s starting position, tools, information, and constraints. The exploit path is left open, and the solution is not known when the challenge is constructed.
This design makes scoring harder than in benchmarks built around planted or documented vulnerabilities. Difficulty has to be predicted before the run and calibrated after the run against models' demonstrated capability. That tradeoff lets FrontierCyber build a balanced benchmark without relying on known exploit paths: enough easier challenges to calibrate the floor, enough hard challenges to probe the frontier, and enough coverage in between to avoid both under-saturating and over-saturating the measurement. While predicted difficulty is necessarily imperfect, it is well-calibrated with respect to expert scores, so a large and growing suite of independent challenges gives a clear signal.
Because FrontierCyber uses real environments, evaluations must be tied to benchmark snapshots and running time. A snapshot fixes the challenge set, environment versions, configurations, verification mechanisms and scoring rubric, and time fixes the difficulty. Model comparisons are meaningful within that context. As environments change and vulnerabilities become public, later snapshots can preserve realism without pretending to be backward compatible in the way static benchmarks are.
FrontierCyber is built for the next stage of offensive-cyber evaluation: models operating against real systems, under fixed conditions, with objectives that matter and solutions that are not known in advance. That makes the benchmark harder to build and harder to score, but it also makes the signal more meaningful. As AI models improve, cyber evaluation will need benchmarks that preserve scientific comparability without retreating to artificial tasks. FrontierCyber is our step in that direction.