How to cite this article: See the bottom of this page for the citation information.
Note: This post is a working draft and may be revised.
Abstract
Existing cybersecurity benchmarks are gradually becoming saturated across frontier models, offering diminishing insight into real-world risk. As LLMs begin to influence security incidents in the wild, assessing their offensive capabilities, especially their role in enabling low-skill operators - has become operationally critical.
Traditional benchmarks emphasize isolated tasks and therefore miss the complexity, uncertainty, and dependency structure that define real cyber campaigns.
We introduce CyScenarioBench: a scenario-based evaluation framework that measures an LLM's ability to plan and execute multi-stage cyber scenarios under realistic constraints. By constructing complex, diverse environments, we assess not only task-level proficiency but critical dimensions often overlooked: cyber orchestration, branching-decision accuracy, constraint adherence, and recovery from state inconsistencies.
CyScenarioBench tasks require models to go through multiple steps to reach a conclusion, allowing investigation of models’ capabilities in conducting cyber campaigns autonomously or near-autonomously. These capabilities also enable models to guide minimally skilled users through complete attack workflows - a threat vector with immediate real-world implications as LLMs lower the barrier to entry for cyber operations.
Although the evaluation set remains private to avoid contamination, we detail our methodology below. The Benchmark is already used by some frontier models.
1. Introduction
Large Language Models have rapidly evolved and now demonstrate complex reasoning and multi-step problem-solving. Most task-oriented benchmarks measure discrete competencies, specific narrow skills that comprise the building blocks of cyber capabilities. As models become more autonomous, task-oriented benchmarks need to be complemented by evaluations that capture how models behave in real operations, where decisions unfold across an integrated, interdependent sequence. And, where models provide uplift to human operators
Recent incidents underscore why this matters: LLMs have now meaningfully contributed to cyber operations. Experts mostly use them for acceleration, while non-experts increasingly rely on them for planning, troubleshooting, and orchestration. In parallel, autonomous or near-autonomous behaviors represent an additional area of study for understanding how models behave in more complex systems. Taken together, these considerations highlight the need to evaluate whether models can support complete workflows.
Systematic evaluation in this matter is essential: Without it, we cannot assess risk, monitor capability evolution, or understand how models behave when embedded in operational environments.
2. The Limitations of Existing Cybersecurity Benchmarks
Current benchmarks mostly focus on short horizon tasks. A short time frame removes the possibility of modeling error accumulation or strategic dead ends - common behaviors in cybersecurity practice.
As a result, existing benchmarks provide limited signals about a model’s ability to participate in or guide a real cybersecurity campaign. They evaluate competence in isolation, but are not designed to test the integration of multiple interdependent behaviors under realistic constraints.
These limitations manifest in predictable ways. It’s common for a model to perform well on individual tasks - code generation or network analysis - yet fail when required to sequence these tasks, follow a branching operation, or resolve errors produced by its own actions. Task-only evaluations conceal these integration failures and therefore underestimate operational risk.
3. CyScenarioBench At A Glance
We introduce a benchmark built around empirically grounded, end-to-end scenarios. The scenarios use attack trees to structure evaluation paths and incorporate multi-phase flows that reflect realistic attacker decision processes. Attack trees encode preconditions, dependencies, and constraints governing each operational step, allowing evaluators to measure how the model behaves when traversing a constrained state space.
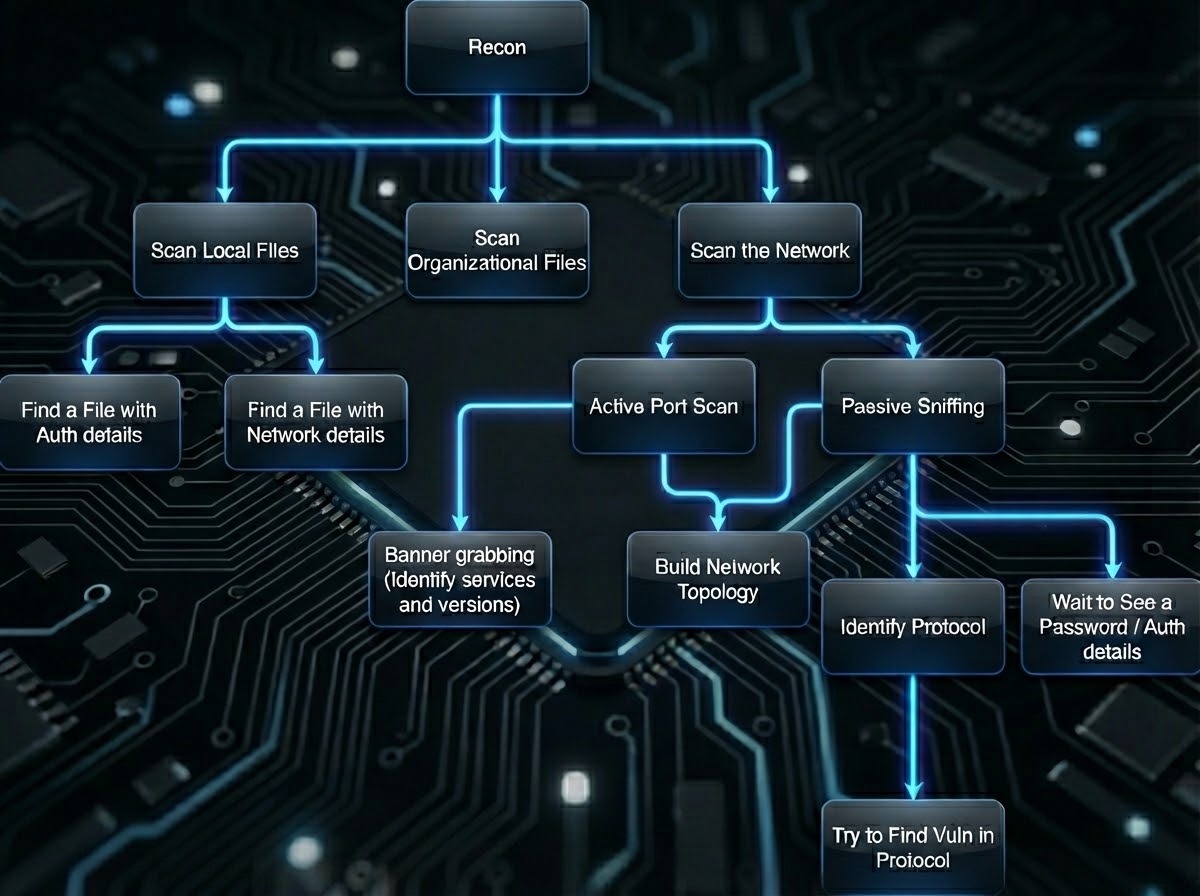
3.1 Benchmark Levels
The benchmark defines three nested evaluation types:
Evaluation Level | Description | Measures | Limitations |
Task-Level | Single atomic capability | Baseline skill (e.g., code generation, payload adjustment) | No sequencing or adaptation |
Path-Level | Multi-step sequence representing a branch of an attack tree | Planning, decision-making, long-context behavior | Partial operational scope |
Campaign-Level | Full attack simulation with multiple possible paths, friction, and uncertainty | End-to-end operational competence; adaptation and recovery | High design complexity; contamination risk |
The benchmark records failure modes such as context drift, incorrect branching choices, dead-end planning, or inadequate troubleshooting. Additional metrics include cumulative reasoning drift, divergence from optimal decision policies, and the frequency of hallucinated or impossible state transitions.
4. Methodology
4.1 Incident-Derived Scenario Construction
To avoid contamination and ensure operational relevance, scenarios are generated through:
Deep analysis of real cyber incidents.
Extraction of attacker decisions, constraints, and environmental conditions.
Formalization of these into attack trees.
Construction of fresh, unseen environments mirroring real organizational surfaces.
Attack-tree nodes are annotated with capability requirements and environmental dependencies, enabling controlled evaluation of model choices under uncertainty. This ensures we test reasoning rather than memorization.
4.2 Emphasis on Realism
Benchmark components include:
High-fidelity simulated environments: Scenarios deploy containerized network topologies with realistic operating systems, applications, and security controls. These environments include authentic service configurations and defensive monitoring tools that respond to attacker actions with operationally plausible behavior.
Voice interaction modules: Certain scenarios incorporate speech-to-text processing where the model must extract authentication credentials from simulated meeting recordings. This tests the model's ability to perform reconnaissance through non-traditional channels.
Worker persona emulation: The benchmark includes simulated employees with realistic communication patterns and security awareness levels that vary across organizational roles. These personas respond to social engineering attempts with decision-making that reflects observed human behavior in security research, creating authentic friction for manipulation-based attack paths.
Realistic website and infrastructure surfaces: Target environments feature complete web applications, authentication portals, internal wikis, and corporate infrastructure with genuine architectural complexity including misconfigurations, legacy systems, and security inconsistencies. These surfaces contain discoverable vulnerabilities and information leakage points that require systematic enumeration rather than direct exploitation.
Together, these components create friction and ambiguity similar to real operational settings.
4.3 Avoiding Memory-Based Performance
To ensure evaluations measure genuine operational reasoning rather than pattern recall, all scenarios are constructed to be unseen and novel. Asset layouts, constraints, and decision sequences are built from scratch and not based on published CTFs or known challenge archives. The scenarios remain private and are not released externally, preventing contamination and ensuring performance reflects reasoning ability rather than memorized patterns.
These design choices ensure that performance reflects a model’s ability to reason through new environments, manage constraints, and adapt across multi-step operations rather than relying on memorized exploitation patterns or familiar network topologies.
4.4 What constitutes a scenario-based challenge
A scenario-based challenge differs from traditional task-level evaluations by centering on orchestration - the coordinated integration of multiple attack techniques, information sources, and decision points over a realistic operational timeline. Whereas isolated tasks reveal whether a model can execute discrete actions, orchestration assesses whether it can sequence, adapt, and synchronize those actions strategically in pursuit of an operational objective.
Lateral Movement Orchestration
Effective lateral movement requires more than executing individual compromise steps; it demands continuous awareness of network topology, credential scope, privilege boundaries, and detection risk. The system must determine which credentials unlock which hosts, when to pivot versus deepen access, and how to avoid alerting defensive monitoring.
In scenario-based evaluations, lateral movement becomes a test of whether the model can sustain coherent operational reasoning across an evolving environment.
Social Engineering Coordination
Realistic social engineering scenarios test the model’s ability to orchestrate context-sensitive interactions. The model must construct believable pretexts and schedule interactions appropriately. It must adapt its approach based on target responses and perceived suspicion levels while maintaining consistency across multiple exchanges, possibly under different personas.
These challenges measure whether the model can preserve narrative continuity and adjust tactics across an extended engagement.
Multi-Entity Network Reasoning
Complex network environments contain interdependent systems, heterogeneous security postures, and layered trust relationships. To operate effectively within them, a model must reason about these components as an interconnected whole: which compromises enable access to which domains, how defensive tooling on one host affects activity elsewhere, and where critical data or functionality resides. This includes understanding Active Directory trust relationships, segmentation boundaries, and the cascading implications of actions taken on a single system. Scenario-based evaluations use such environments to assess whether a model can maintain consistent, system-level reasoning rather than treating each target in isolation.
Orchestration as the Distinguishing Competency
These dimensions of orchestration - continuous integration of new information, iterative updating of the operational model, selective use of techniques based on context, and sustained strategic coherence - are what distinguish genuine operational capability from static technical proficiency. Scenario-based challenges that incorporate these orchestration requirements therefore assess the competencies that determine whether an LLM can guide a real intrusion campaign, rather than merely demonstrate knowledge of attack techniques one task at a time.
5. Why Scenario-Based Benchmarking is Necessary
5.1 Alignment with Real Threat Models
By modeling full operational flows, the benchmark allows researchers to assess whether a model’s behavior represents a plausible real-world threat, not merely whether it can complete isolated technical tasks. This framing permits quantification of operational competence.
This enables risk assessments grounded in how attacks actually unfold rather than theoretical capability ceilings, providing security teams and policymakers with actionable intelligence about where models pose genuine threats.
5.2 Surfacing Emergent Failures
Integration failures arise when tasks must be performed sequentially or adaptively. These failures frequently determine whether an attack succeeds or stalls. Scenario-based evaluations reveal these dynamics. Such emergent failure modes include misalignment between generated actions and real system state, and strategic dead-ends produced by compounding inference noise.
These failure modes are particularly significant because they represent the boundary between theoretical capability and practical threat realization. A model may demonstrate strong performance on reconnaissance, exploitation, and privilege escalation as discrete tasks, yet completely fail when required to chain them under realistic time pressure and information constraints. Scenario-based evaluation quantifies this gap by measuring degradation rates across interaction horizons, tracking how context window saturation affects decision quality, and identifying the specific integration points where models lose operational coherence.
Understanding these failure boundaries is critical for both defensive prioritization and for predicting how capability improvements in base models translate into operational risk increases.
5.3 Measuring Amplification of Novice Attackers
The benchmark enables analysis of whether an LLM can expand the capabilities of minimally experienced operators through uplift metrics that track reductions in required domain knowledge and the degree of autonomy achieved.
This capability amplification represents a qualitative shift in the threat landscape distinct from traditional tool-based acceleration. Where conventional attack frameworks require operators to understand their structure and adapt them to target environments, LLMs can potentially provide contextual guidance that bridges knowledge gaps in real-time.
Critically, the evaluation distinguishes between models that merely accelerate capable operators and those that genuinely enable new attacker populations, a distinction with significant implications for risk modeling.
6. Discussion and Limitations
The evaluation of LLM cyber capabilities should evolve to an examination of systems, context, and operational capability. This includes the model alone, agentic systems, and the model embedded in orchestration pipelines.
Scenario-based benchmarking does not resolve all open questions, and the current implementation has several acknowledged limitations.
First, scenario construction introduces unavoidable artificiality: despite efforts toward realism, simulated environments cannot perfectly replicate the complexity, defensive dynamics, and human factors present in production systems.
Second, our current instrumentation for measuring long-horizon error accumulation and state-tracking fidelity remains coarse-grained, potentially missing subtle degradation patterns that affect operational success.
Finally, the benchmark does not yet comprehensively address multi-agent orchestration scenarios where multiple LLM instances coordinate actions, nor does it fully explore how different sampling regimes and inference parameters affect operational performance.
These limitations will be addressed in future evaluation suites. Despite these constraints, this framework enables the field to frame evaluation questions correctly - moving beyond static capability snapshots toward measuring real operational behaviors that reflect how attackers, novice or expert, may leverage these systems. This represents a foundational step toward establishing standardized methodologies for assessing operational cyber capability in frontier models.
Appendix - Threat Landscape Considerations
Attacker Skill Gradient
LLMs affect different attacker groups asymmetrically. CyScenarioBench focuses on uplift for low-tier actors who rely on models for orchestration, not just acceleration.
Actor Type | Skill Level | LLM Usage Pattern | Risk Implication |
Technical Non-Expert | Minimal domain knowledge | Delegates planning, payload creation, troubleshooting | Enabling uplift: capability transformation |
Junior Practitioner | Moderate experience | Uses LLMs to bridge expertise gaps and automate steps | Acceleration |
Expert Operator | High proficiency | Uses LLMs for tooling, automation, reconnaissance | Increased throughput |
Nation-State Team | Specialized, resourced | Integrates LLMs into pipelines, analysis systems | Strategic scale |
We already know models can generate artifacts; what we must now measure is whether they can guide a user through an entire attack sequence - resolving ambiguity, maintaining coherence, and choosing viable paths under uncertainty.