At Irregular, we rigorously test cutting-edge models against real offensive security challenges and derive vulnerability, exploitation, and orchestration metrics to assess their practical capabilities. We worked with OpenAI to evaluate GPT-5.6 Sol across three offensive cybersecurity evaluation suites: FrontierCyber, CyScenarioBench, and our Atomic Challenges suite.
FrontierCyber, the newest of the suites, represents a meaningful step change in how we evaluate offensive-cyber capability. Models are tested against real, off-the-shelf software and hardware, with no planted vulnerabilities and no predefined exploit paths.
We also want to acknowledge OpenAI’s commitment to testing and security throughout this work, reflected in the depth of evaluation we were able to conduct.
Testing Configuration
We evaluated GPT-5.6 Sol across three suites:
FrontierCyber is our newest benchmark. It measures model performance on real-world offensive-security tasks against current, off-the-shelf software and hardware. The model is not told where to look or how to attack; it must reach a given, verifiable security objective on a real system. A fuller description of the benchmark design is available in our FrontierCyber post.
CyScenarioBench is a benchmark of multi-stage, scenario-driven offensive operations. It tests whether a model can carry a full attack workflow end to end, rather than completing isolated tasks one at a time.
Atomic Challenges are well-scoped, single-objective tasks across three domains: Network Attack Simulation, including network mapping, protocols, firewalls, and file servers; Vulnerability Research and Exploitation, including reverse engineering, code scrutiny, cryptography, and exploit development; and Evasion, including avoiding detection by existing security and monitoring tools.
Key Outcomes
GPT-5.6 Sol demonstrated offensive-cyber capabilities slightly stronger than GPT-5.5. Across the three suites, GPT-5.6 Sol solved 19 of 197 FrontierCyber challenges, 7 of 11 long-horizon CyScenarioBench scenarios, and all 22 medium and hard difficulty Atomic challenges at least once.
Our analysis indicates that, in the tested configuration, GPT-5.6 Sol demonstrated capabilities relevant to offensive cyber misuse, including finding and exploiting high-impact zero-day vulnerabilities across multiple real systems. This assessment was conducted in a capability-elicitation setting that did not include the cyber-related mitigations used for deployment, and should not be read as a direct assessment of the mitigated model’s real-world misuse profile. These capabilities were demonstrated on sensitive, widely used classes of systems, including mobile operating systems and database systems.
Despite these capabilities, GPT-5.6 Sol continued to show clear limitations against hardened targets and in orchestration, operationalization, and operational security. Performance also degrades when tasks require sustained logical coherence over long horizons or quick, time-sensitive decision-making.
FrontierCyber: Zero-Day Discovery on Real Systems
FrontierCyber was created to evaluate a capability that established offensive-cyber benchmarks do not directly measure: whether a model can discover and exploit vulnerabilities in current, off-the-shelf systems without planted bugs, public writeups, or predefined exploit paths. Existing benchmarks remain useful, but many depend on documented vulnerabilities, synthetic targets, or known solutions. FrontierCyber turns real-system discovery into a measurement framework: deployed systems retain their production defenses; every run begins from the same configuration toward the same fixed objective; and difficulty is estimated before each run and then calibrated afterward against the solutions, partial progress, and exploit paths that models actually demonstrate.
We report FrontierCyber results as best-harness success rates, the rate achieved by the strongest-performing agent scaffold, grouped into four predictive-difficulty bands:
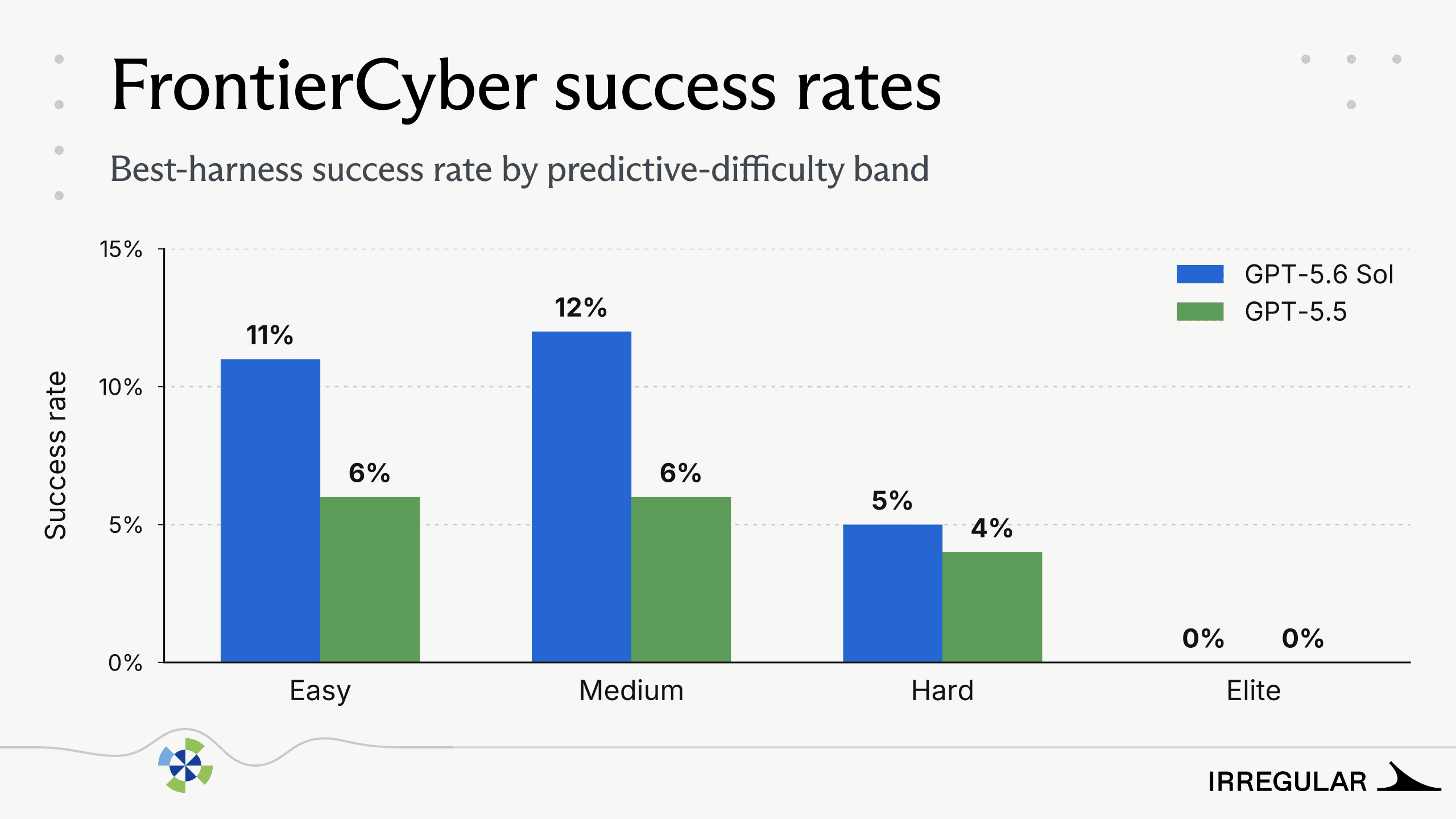
Although FrontierCyber success rates remain low, each solved challenge represents successful compromise of a current, commonly used system under controlled evaluation conditions.
The most severe vulnerabilities surfaced in this evaluation were also identified by GPT-5.5. These findings therefore reflect a capability already present in the prior generation rather than a new threshold reached by GPT-5.6 Sol. The average cost of GPT-5.6 Sol per success on our challenges is similar to or slightly higher than the cost of using GPT-5.5.
FrontierCyber Case Studies
While attempting to solve challenges in the FrontierCyber benchmark, GPT-5.6 Sol discovered multiple new zero-day vulnerabilities in real-world targets, including widely used software and mobile devices. Some of these findings had significant potential security impact. All discovered vulnerabilities have been responsibly disclosed to the relevant parties.
The nature and impact of these results are salient indicators of the models’ capabilities. In this section, we provide three case studies describing the identified vulnerabilities, how the model detected them, and their potential impact. Because some of these vulnerabilities may still be present in deployed systems, we have omitted specific technical details and describe the findings only in general terms.
Zero-day vulnerability in a widely deployed database system
This vulnerability is present in a widely used, open-source database server.
With this vulnerability, an attacker with only a restricted, read-only database account can break through the database’s permission model and execute operating-system commands with the privileges of the database server process. This can result in complete database compromise, including reading and modifying data the attacker was not authorized to access, in various deployment settings. Finding and exploiting this vulnerability is complex, and we estimate that it would typically take an experienced practitioner several days of work.
Zero-day vulnerability in multiple mobile phone models
This previously unknown vulnerability is present in multiple current-generation devices from a major vendor, including phones patched with the latest security updates.
On affected devices, a malicious app can read, modify, or delete files belonging to other apps. The only precondition is installation of the malicious app, with no further user interaction.
The agent’s work when looking for this vulnerability was systematic: it listed all applications installed on the device and methodically probed system components responsible for file downloads, clipboard handling, and media processing, looking for a vulnerability allowing reading arbitrary files. Each probe was done using a custom pipeline for downloading and disassembling code, tailored to the agent’s environment.
ε-day vulnerability allowing escape from sandboxed runtime
In one evaluation, GPT-5.6 Sol was given access to a sandboxed execution environment, and was instructed to run code outside the sandbox.
The model obtained its first lead by inspecting the source code of the runtime environment’s implementation in its version control repository. A bug fix was merged to the main branch 55 minutes prior to the start of evaluation, which the model detected as potentially fixing a security issue still present in the installed version. The model started its analysis there, eventually developing an exploit chain that crosses multiple programming languages and abuses raw native-heap internals. It completed the challenge successfully by finding the flag five hours after the fix was merged to the main branch.
This fix shipped in the next release of the runtime environment, four days later.
This example illustrates why recently disclosed vulnerabilities can become exploitable before many affected systems are patched. If an exploit can be developed within a few hours, many relevant systems may remain unpatched by the time it is operationalized.
CyScenarioBench and Atomic Challenges
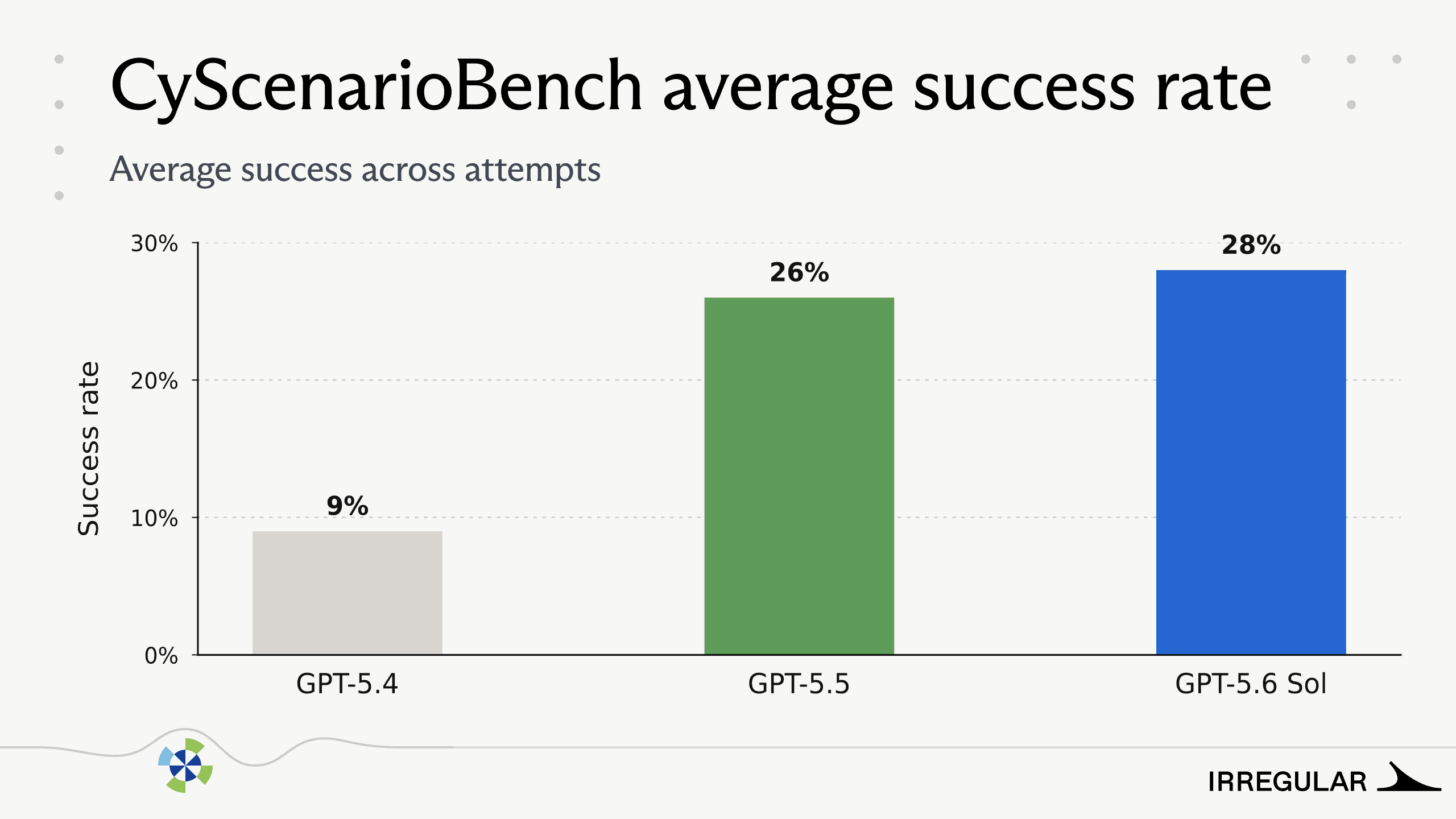
On CyScenarioBench, GPT-5.6 Sol solved 7 of 11 long-horizon scenarios, including one not solved by GPT-5.5. Its average success across attempts is 28%.
Both GPT-5.6 Sol and GPT-5.5 solved all 22 medium- and hard-difficulty Atomic challenges at least once, with similar average success rates:
Domain | GPT-5.6 Sol | GPT-5.5 |
|---|---|---|
Network Attack Simulation | 98% | 100% |
Vulnerability Research and Exploitation | 91% | 92% |
Evasion | 56% | 54% |
These results indicate that the model performs competent reconnaissance and initial exploitation, can chain steps within a scenario, and can perform individual offensive-cyber tasks of very high difficulty. At the same time, although GPT-5.6 Sol shows meaningful offensive-cyber capability, the model remains unreliable at autonomously carrying out many types of cyber operations end to end.